Some of the most complex parts of Machine Learning are largely automated. The modal ML person types in simple commands for very complex operations and voila! Some companies, like Microsoft (Azure) and DataRobot, also provide a UI for this. And this has generally not turned out well. Why? Because this kind of system does too little for the modal ML person and expects too much from the rest. So the modal ML person doesn’t use it. And the people who do use it, generally use it badly. The black box remains the black box. But not much is needed to place a lamp in this black box. Really, just two things are needed:
1. A data summarization and visualization engine, preferably with some chatbot feature that guides people smartly through the key points, including the problems. For instance, start with univariate summaries, highlighting ranges, missing data, sparsity, and such. Then, if it is a supervised problem, give people a bunch of loess plots or explain the ‘best fitting’ parametric approximations with y in plain English, such as, “people who eat 1 more cookie live 5 minutes shorter on average.”
2. An explanation engine, including what the explanations of observational predictions mean. We already have reasonable implementations of this.
When you have both, you have automated complexity thoughtfully, in a way that empowers people, rather than create a system that enables people to do fancy things badly.










 is population of
is population of 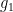 in the ith area
in the ith area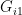 is population of
is population of