Say that there is a donation solicitation company. Say that there are 100M potential donors they can reach out to eachyear. Let’s also assume that the company gets paid on a contingency fee basis, getting a fixed percentage of all donations.
The company currently follows the following process: it selects 10M potential donors from the list using some rules and reaches out to them. The company gets donations from 2M donors. Also, assume that agents earn a fixed percentage of the dough they bring in.
What’s profit-maximizing staffing?
The company’s optimal strategy for staffing (depending on the risk preference) is:


where

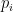



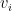



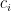
Modeling
The data we have the greatest confidence in pertains to cases where we tried and observed an outcome. The data for the 10M can look like this:
cost_of_contact, donation
10, 0
15, 1
20, 100
25, 0
30, 1000
.., ..We can use this data to learn a regression within the 10M and then use the model to predict the rank. If you use the model to rank the 10M you get next year, you can get greater profits from not pursuing the 8M. If you use it to rank the remaining 90M, you are making the assumption that donors who were not selected but are otherwise similar to those who were chosen, are similar in their returns. It is likely not the case.
To get better traction on the 90M, you need to get new data, starting with a random sample, and using deep reinforcement learning to figure out the kind of donors who are profitable to reach out to.