Prediction Errors: Using ML For Measurement
Say you want to measure how often people visit pornographic domains over some period. To measure that, you build a model to predict whether or not a domain hosts pornography. And let’s assume that for the chosen classification threshold, the False Positive rate (FP) is 10\% and the False Negative rate (FN) is 7\%. Here below, we discuss some of the concerns with using scores from such a model and discuss ways to address the issues.
Let’s get some notation out of the way. Let’s say that we have

users and that we can iterate over them using

. Let’s denote the total number of unique domains—domains visited by any of the
users at least once during the observation window—by

. And let’s use

to iterate over the domains. Let’s denote the number of visits to a domain
by user
by
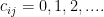
. And let’s denote the total number of unique domains a person visits (
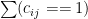
) using
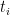
. Lastly, let’s denote predicted labels about whether or not each domain hosts pornography by

, so we have
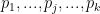
.
Let’s start with a simple point. Say there are 5 domains with
:
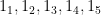
. Let’s say user one visits the first three sites once, and let’s say that user two visits all five sites once. Given 10\% of the predictions are false positives, the total measurement error in user one’s score
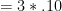
and the total measurement error in user two’s score

. The general point is that total false positives increase as a function of predicted
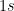
. And the total number of false negatives increase as the number of predicted
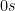
.
Read more below.