Many times within a narrow product category like breakfast cereals, ice cream tubs, etc., the prices of different varieties within a brand are the same. The same pattern continues in many ice cream stores where you are charged for the quantity instead of the flavor or the vessel in which ice cream is served. It is unlikely that input costs are the same across varieties. So what explains it? It could be that the prices are the same because the differences in production costs are negligible. Or it could be that retailers opt for uniform pricing because of managerial overhead (see also this paper). Or there could be behavioral reasons. Consumers may shop in a price-conscious manner if the prices are different and may buy less.
Breakfast cereals have another nuance. As you can see in the graphic above, the weight of the ‘family size’ box (which has the same size and shape) varies. It may be because there are strong incentives to keep the box size the same. This in turn may be because of stocking convenience or behavioral reasons, e.g., consumers may think they are judging between commensurate goods if the boxes are the same size. (It could also be that consumers pay for volume not weight.)
Lack of Incentives for Producing High-Quality Software. Software’s role in enabling and accelerating research cannot be overstated. But the incentives for producing software in academia are still very thin. One reason is that people do not cite the software they use; the academic currency is still citations.
Lack Ways to Track the Consequences of Software Bugs (Errors). (Quantitative) Research outputs are a function of the code researchers write themselves and the third-party software they use. Let’s assume that the peer review process vets the code written by the researcher. This leaves code written by third-party developers. What precludes errors in third-party code? Not much. The code is generally not peer-reviewed though there are efforts underway. Conditional on errors being present, there is no easy way to track bugs and their impact on research outputs.
Developers Lack Data on How the Software is Being (Mis)Used. The modern software revolution hasn’t caught up with the open-source research software community. Most open-source research software is still distributed as a binary and emits no logs that can be analyzed by the developer. The only way a developer becomes aware of an issue is when a user reports the issues. This leaves errors that don’t cause alerts or failures, e.g., when a user user passes data that is inconsistent with the assumptions made when designing the software, and other insights about how to improve the software based on usage.
Conventional Reference Lists Are the Wrong Long-Term Solution for #1 and #2
Unlike ideas, which need to be explicitly cited, software dependencies are naturally made explicit in the code. Thus, there is no need for conventional reference lists (~ a bad database). If all the research code is committed to a system like Github (Dataverse lacks the tools for #2) with enough meta information about (the precise version of the) third-party software being used, e.g., import statements in R, etc., we can create a system like the Github dependency graph to calculate the number of times software has been used (and these metrics can be shown on Google Scholar, etc.) and also create systems that trigger warnings to authors when consequential updates to underlying software are made. (See also https://gojiberries.io/2019/03/22/countpy-incentivizing-more-and-better-software/).
Conventional reference lists may however be the right short-term solution. But the goalpost moves to how to drive citations. One reason researchers do not cite software is that they don’t see others doing it. One way to cue that software should be cited is to show a message when the software is loaded — please cite the software. Such a message can also serve as a reminder for people who merely forget to cite the software. For instance, my hunch is that one of the stargazer has been cited more than 1,000 times (June 2023) is because the package produces a message .onAttach to remind the user to cite the package. (See more here.)
Solution for #3
Spin up a server that open source developers can use to collect logs. Provide tools to collect remote logs. (Sample code.)
p.s. Here’s code for deriving software citations statistics from replication files.
Consider the following scenario: There are multiple firms looking to fill identical jobs. And there are multiple eligible workers given each job opening. Both the company and the workers have perfect information, which they are able toacquire without cost. Assume also that employees can switch jobs without cost. Under these conditions, it is expensive for employers to discriminate. If company A prejudicially excludes workers from Group X, company B can hire the same workers at a lower rate (given that the demand for them is lower) and outcompete company A. It thus reasons thatdiscrimination is expensive. Some people argue that for the above reasons, we do not need anti-discrimination policies.
There is a crucial, well-known, but increasingly under-discussed nuance to the above scenario. When consumers or co-workers also discriminate, it may be profit-maximizing for a firm to discriminate. And the point fits the reality of 60 years ago when many hiring ads specifically banned African Americans from applying (‘Whites only’, ‘Jews/Blacks need not apply’, etc.), many jobs had dual wage scales, and explicitly segregated job categories existed. A similar point applies to apartment rentals. If renters discriminate by the race of the resident, the optimal strategy for an apartment block owner is to discriminate by race. Indian restaurants provide another example. If people prefer Brahmin cooks (for instance, see here, here, and here), the profit-maximizing strategy for restaurants is to look for Brahmin cooks (for instance, see here). All of this is to say that under these conditions, you can’t leave it to the markets to stop discrimination.
Many widely used machine-learning models rely on copyrighted data. For instance, Google finds the most relevant web pages for a search term by relying on a machine learning model trained on copyrighted web data. But the use of copyrighted data by machine learning models that generate content (or give answers to search queries than link to sites with the answers) poses new (reasonable) questions about fair use. By not sharing the proceeds, such systems also kill the incentives to produce original content on which they rely. For instance, if we don’t incentivize content producers, e.g., people who respond to Stack Overflow questions, the ability of these models to answer questions in new areas is likely to be lower. The concern about fair use can be addressed by training on data from content producers that have opted to share their data. The second problem is more challenging. How do you build a system that shares proceeds with content producers?
One solution is licensing. Either each content creator licenses data independently or becomes part of a consortium that licenses data in bulk and shares the proceeds. (Indeed Reddit, SO, etc. are exploring this model though they have yet to figure out how to reward creators.) Individual licensing is unlikely to work at scale so let’s interrogate the latter. One way the consortium could work is by sharing the license fee equally among the creators, perhaps pro-rated by the number of items. But such a system can easily be gamed. Creators merely need to add a lot of low-quality content to bump up their payout. And I expect new ‘creators’ to flood the system. In equilibrium, it will lead to two bad outcomes: 1. An overwhelming majority of the content is junk. 2. Nobody is getting paid much.
The consortium could solve the problem by limiting what gets uploaded but it is expensive to do. Another way to solve the problem is by incentivizing at a person-item level. There are two parts to this—establishing what was used and how much and pro-rating the payouts by value. To establish what item was used in what quantity, we may want a system that estimates how similar the generated content is to the underlying items. (This is an unsolved problem.) The payout would be prorated by similarity. But that may not incentivize creators who value their content a lot, e.g., Drake, to be part of the pool. One answer to that is to craft specialized licensing agreements as is commonly done by streamlining platforms. Another option would be to price the contribution. One way to price the contribution would be to generate counterfactuals (remove an artist) and price them in a marketplace. But it is possible to imagine that there is natural diversity in what is created and you can model the marginal contribution of an artist. The marketplace analogy is flawed because there is no one marketplace. So the likely way out is for all major marketplaces to subscribe to some credit allocation system.
Money is but one reason why people produce. Another reason people produce content is so that they can get rewarded for their reputations, e.g., SO. Generative systems built on these data however have not been implemented in a way to keep these markets intact. The current systems reduce traffic and do not give credit to the people whose answers they learn from. The result is that developers have less of an incentive to post to SO. And SO licensing its content doesn’t solve this problem. Directly tying generative models to user reputations is hard partly because generative models are probabilistically mixing things and may not produce the right answer but if the signal is directionally correct, it could be fed back to reputation scores of creators.
I recently conducted a survey on Lucid and posed a short quiz to test basic numeracy:
A man writes a check for $100 when he has only $70.50 in the bank. By how much is he overdrawn? — $29.50, $170.50, $100, $30.50
Imagine that we roll a fair, six-sided die 1000 times. Out of 1000 rolls, how many times do you think the die would come up as an even number? — 500, 600, 167, 750
If the chance of getting a disease is 10 percent, how many people out of 1,000 would be expected to get the disease? — 100, 10, 1000, 500
In a sale, a shop is selling all items at half price. Before the sale, the sofa costs $300. How much will it cost on sale? — $150, $100, $200, $250
A second-hand car dealer is selling a car for $6,000. This is two-thirds of what it cost new. How much did the car cost new? — $9,000, $4,000, $12,000, $8,000
In the BIG BUCKS LOTTERY, the chances of winning a $10 prize are 1%. What is your best guess about how many people would win a $10 prize if 1000 people each buy a single ticket from BIG BUCKS? — 10, 1, 100, 50
I surveyed 800 adult Americans. Of the 800, only 674 respondents (about 84%) cleared the attention check—a question designed to test if the respondents were paying attention or not. I limit the analysis to these 674 respondents.
A caveat before the results. I do not adjust the scores for guessing.
Of these respondents, just about a third got all the answers correct. Another quarter got 5 out of 6 correct. Another 19% got 4 out of 6 right. The remaining 20% got 3 or fewer questions right. The table below enumerates the item-wise results.
Item
Proportion Correct
Overdraft
.83
Dice
.68
Disease
.88
Sofa Sale
.97
Car
.66
Lottery
.63
The same numbers are plotted below.
p.s. You may be interested in reading this previous blog based on MTurk data.
Hardly a day passes without a major company announcing the release of a new scientific paper or code around a powerful technique. But why do so many companies open source (via papers and code) so many impactful technologies almost as soon as they are invented? The traditional answers—to attract talent, and to generate hype—are not compelling. Let’s start with the size of the pie. Stability AI, based solely on an open-source model quickly raised money at a valuation of $1B. Assuming valuations bake in competitors, lots of money was left on the table in this one case. Next, come to the credit side — literally. What is the value of headlines (credit) during a news cycle, which usually lasts less than a day? As for talent, the price for the pain of not publishing ought not to be that high. And the peculiar thing is that not all companies seem to ooze valuable IP. For instance, prominent technology companies like Apple, Amazon, Netflix, etc. don’t ooze much at all. All that suggests that this is a consequence of poor management. But let’s assume for a second that the tendency was ubiquitous. There could be three reasons for it. First, it could be the case that companies are open-sourcing things they know others will release tomorrow to undercut others or to call dibs on the hype cycle. Another reason could be that they release things for the developer ecosystem on their platform. Except, this just happens not to be true. Another plausible answer is that when technology moves at a really fast pace — what is hard today is easy tomorrow— the window for monetization is small and companies forfeit these small benefits and just skim the hype. (But then, why invest in it in the first place?)
Say that people can be easily identified by characteristic C. Say that the average tip left by people of group C_A is smaller than !C_A with a wide variance in tipped amounts within each group. Let’s assume that the quality of service (two levels: high or low) is pro-rated by the expected tip amount. Let’s assume that the tip left by a customer is explained by the quality of service. And let’s also assume that the expected tip amount from C_A is low enough to motivate low-quality service. The tip is provided after the service. Assume no-repeat visitation. The optimal strategy for the customer is to not tip. But the service provider notices the departure from rationality from customers and serves accordingly. If the server had complete information about what each person would tip, then the service would be perfectly calibrated by the tipped amount. However, the server can only rely on crude surface cues, like C, and estimate the expected value of the tip. Given that, the optimal strategy for the server is to provide low-quality service to C_A, which would lead to a negative spiral.
A host of cloud services are missing the core functionality needed to build businesses on top of the services. Powerful services on mature platforms like Google Vision, etc., have a common set of deficiencies—they do not allow clients to send information about preferred latency and throughput (for a price), and they do not allow clients to programmatically define SLAs (again, for a price). (If you read the documents of Google Vision, there is no mention of how quickly the API will return the answer for a document of a particular size.) One price for ~all requesters is the norm. Not only that, in the era of ‘endless scalable compute,’ throttling is ubiquitous.
There are two separate ideas here. The first is about how to solve one-off needs around throughput and latency. For a range of services, we can easily provide a few options that price in bandwidth and server costs. For a certain volume of requests, the services may require that the customer send a request outlining the need with enough lead time to boot new servers. The second idea is about programmatically signing SLAs. Rather than asking customers to go back and forth with Sales around custom pricing for custom needs, providing a few options for a set of standard use cases may be more expedient.
Some low-level services like s3 work almost like that today. But the move to abstracting out this paradigm to higher-level services has largely not begun. I believe it is time.
Traditionally software has been distributed as a binary. The customer “grants” the binary a broad set of rights on the machine and expects the application to behave, e.g., not snoop on personal data, not add the computer to a botnet, etc. Most SaaS can be delivered with minor alterations to the above—finer access control and usage logging. Such systems work on trust—the customer trusts that the vendor will do the right thing. It is a fine model but does not work for the long tail. For the long tail, you need a system that grants limited rights to the application and restricts what data can be sent back. This kind of model is increasingly common on mobile OS but absent on many other “platforms.”
The other big change over time in software has been how much data is sent back to the application maker. In a typical case, the SaaS application is delivered via a REST API, and nearly all the data is posted to the application’s servers. This brings up issues about privacy and security, especially for businesses. Let me give an example. Say there is an app that can summarize documents. And say that a business has a few million documents in a Dropbox folder on which it would like to run this application. Let’s assume that the app is delivered via a REST API, as many SaaS apps are. And let’s assume that the business doesn’t want the application maker to ‘keep’ the data. What’s the recourse? Here are a few options:
Trust me. Large vendors like Google can credibly commit to models where they don’t store customer data. To the extent that storing customer data is valuable to the application developer, the application developer can also use price discrimination, providing separate pricing tiers for cases where the data is logged and where it isn’t. For example, see the Google speech-to-text API.
Trust but verify. The application developer claims to follow certain policies, but the customer is able to verify, for e.g., audit access policies and logs. (A weaker version of this model is relying on industry associations that ‘certify’ certain data handling standards, e.g., SOC2.)
Trusted third-party. The customer and application developer give some rights to a third party that implements a solution that ensures privacy and protects the application developer’s IP. For instance, AWS provides a model where the customer data and algorithm are copied over to an air-gapped server and the outputs written back to the customer’s disk.
Of the three options, the last option likely reduces friction the most for long tail applications. But there are two issues. First, such models are unavailable on a wide variety of “platforms,” e.g., Dropbox, etc. (or easy integrations with the AWS offering are uncommon). The second is that air-gapped copying is but one model. A neutral third party can provide interesting architectures, including strong port observability and customer-in-the-loop “data emission” auditing, etc.
It used to be that retail prices of generic products like coffee mugs, soap, etc., moved slowly. Not anymore. On major web retailers like Amazon, for a range of generic household products, the variation in prices over short periods of time is immense. For instance, on 12-Piece Porcelain, 12 Oz. Coffee Mug Set, the price ranged between $20.50 and $35.71 over the last year or so, with a hefty day-to-day variation.
On PCPartPicker, the variation in prices for Samsung SSD is equally impressive. Prices zig-zag on multiple sites (e.g., Dell, Adorama) by $100 over a matter of days multiple times over the last six months. (The cross-site variation—price dispersion—at a particular point in time is also impressive.)
What explains the within-site over-time variation? One reason could be supply and demand. There are three reasons I am skeptical of the explanation. First, on Amazon, the third-party new item price time series and Amazon price time series do not appear to be correlated (statistics by informal inspection or as one of my statistics professors used to call it—the ocular distortion test—so caveat emptor). On PCPartPicker, you see much the same thing: the cross-retailer price time series frequently crossover. Second, related to the first point, we should see a strong correlation in overtime price curves across substitutes. We do not. Third, the demand for generic household products should be readily forecastable, and the optimal dry good storage strategy is likely not storing just enough. Further, I am skeptical of strong non-linearities in the marginal cost of furnishing an item that is not in the inventory—much of it should be easily replenishable.
The other explanation is price exploration, with Amazon continuously exploring the profit-maximizing price. But this is also unpersuasive. The range over which the prices vary over short periods of time is too large, especially given substitutes and absent collusion. Presumably, companies have thought about the negative consequences of such wide price exploration bands. For instance, you cannot build a reputation as the ‘cheapest’ (unless there is coordination or structural reason for prices to move together.)
So I come empty when it comes to explanations. There is the crazy algorithm theory—as inventory dwindles, Amazon really hikes the price, and when it sees no sales, it brings the price right back down. It may explain the frequent sharp movements over a fixed band that you see in some places but plausibly doesn’t explain a lot of the other patterns we see.
Forget the explanations and let’s engage with the empirical fact. My hunch is that customers are unaware of the striking variation in the prices of many goods. Second, if customers become aware of this, their optimal strategy would be to use sites like CamelCamelCamel or PCPartPicker to pick the optimal time for purchasing a good. If retailers are somehow varying prices to explore profit-maximizing pricing (minus price discrimination based on location, etc.), and if all customers adopt the strategy of timing the purchase, then, in equilibrium, the retailer strategy would reduce to constant pricing.
p.s. I found it funny that there are ‘used product’ listings for soap.
p.p.s. I wrote about the puzzle of price dispersion on Amazon here.
In particular, in 521 villages in Haryana, we provided information on monthly immunization camps to either randomly selected individuals (in some villages) or to individuals nominated by villagers as people who would be good at transmitting information (in other villages). We find that the number of children vaccinated every month is 22% higher in villages in which nominees received the information.
The buildings, which are social units, were randomized to (1) targeting 20% of the women at random, (2) targeting friends of such randomly chosen women, (3) targeting pairs of people composed of randomly chosen women and a friend, or (4) no targeting. Both targeting algorithms, friendship nomination and pair targeting, enhanced adoption of a public health intervention related to the use of iron-fortified salt for anemia.
Coupon redemption reports showed that unadjusted adoption rates were 13.6% (SE = 1.5%) in the friend-targeted clusters, 11.2% (SE = 1.4%) in pair-targeted clusters, 9.1% (SE = 1.3%) in the randomly targeted clusters, and 0% in the control clusters receiving no intervention.
Targeting “structurally influential individuals,” e.g., people with lots of friends, people who are well regarded, etc., can lead to larger returns per ‘contact.’ This can be a useful thing. And as the studies demonstrate, finding these influential people is not hard—just ask a few people. There are, however, a few concerns:
One of the concerns with any targeting strategy is that it can change who is treated. When you use network-based targeting, it biases the treated sample toward those who are more connected. That could be a good thing, especially if returns are the highest on those with the most friends, like in the case of curbing contagious diseases, or it could be a bad thing if the returns are the greatest on the least connected people. The more general point here is that most ROI calculations for network targeting have only accounted for costs of contact and assumed the benefits to be either constant or increasing in network size. One can easily rectify this by specifying the ROI function more fully or adding “fairness” or some kind of balance as a constraint.
There is some stochasticity that stems from which person is targeted, and their idiosyncratic impact needs to be baked into standard error calculations for the ‘treatment,’ which is the joint of whatever the experimenters are doing and what the individual chooses to do with the experimenter’s directions (compliance needs a more careful definition). Interventions with targeting are liable to have thus more variable effects than without targeting and plausibly need to be reproduced more often before they used as policy.
Software engineering has changed dramatically in the last few decades. The rise of AWS, high-level languages, powerful libraries, and frameworks increasingly allow engineers to focus on business logic. Today, software engineers spend much of their time writing code that reasons over data to show something or do something. But how engineering is done has not caught up in some crucial ways:
Software Development Tools. Most data scientists today work in a notebook on a server where they heavily interact with the data as they refine the code (algorithm). Most engineers still work locally without access to production data. Part of the reason engineers don’t have access to the data is because they work locally—for security and compliance reasons, access to production data from the local machine is banned in most places. Plausibly, a bigger reason is that engineers are stuck in a paradigm where they don’t think access to production data is foundational to faster, higher-quality software development. This belief is reflected in the ad-hoc solutions to the problem that are being tried across the industry, e.g., synthetic data (which is hard to create, maintain, and scale).
Data Modeling. The focus on data modeling has sharply decreased over time in many companies. There are at least four underlying forces behind this trend. First, the combination of the volume of the data being generated and the rise of cheap blob storage (combined with the fact that computing power is comparatively vastly more expensive today) incentivizes the storage of unstructured data. Second, agile development, which prioritizes customer-facing progress over short time units, may cause underinvestment in costly, foundational work (see here). Third, the engineering organizations are changing in that the producers of the data are no longer seen as owners of the data. The fourth and last point is perhaps the most crucial—the surfeit of data has led to some magical thinking about the ease with which data can be used to power insights. Our ability to derive business insights from unstructured and dirty data, except for a small minority of cases, e.g., search, doesn’t exist. The only thing the surfeit of data has done is that it has widened and deepened the pool of insights that can be delivered. It hasn’t made it any easier to derive those insights, which continue to rely on good old-fashioned manual work to understand the use case and curate and structure the data appropriately. (It also then becomes an opportunity for building software.)
Engineers pay the price of not investing in data modeling by making the code more complex (and hence, more unmaintainable) and by allocating time to fix “bugs.” (The reason I put the word bugs in air quotes is because obvious consequences of a bad system should not be called bugs.)
Data Drift. Machine Learning Engineers (MLEs) obsess about it. Most other engineers haven’t ever heard of the term. Everyone should worry. Technically, the only difference between using ML and engineering for rule creation is that ML auto-creates rules while conventional engineering relies on handcrafting the rules. Both systems test the efficacy of their rules on the current data. Both systems assume that the data will not drift. Only MLEs monitor the data, thinking hard about what data the rules work for and how to monitor data drift. Other engineers need to sign up.
The solutions are as simple as the problems are immense: invest in data quality, data monitoring, and data models. To achieve that, we need to change how organizations are structured, how they are run, and what engineers think the hard problems are.
The phrase “noise in decision making” brings to mind “random” error. Scientists, however, shy away from random error. Science is mostly about systematic error, except, perhaps, quantum physics. So Kahneman et al. conceive of noise as seemingly random error that is a result of unmeasured biases. For instance, research suggests that heat causes bad mood. And bad mood may, in turn, cause people to judge more harshly. If this were to hold, the variability in judging stemming from the weather can end up being interpreted as noise. But, as is clear, there is no “random” error, merely bias. Kahneman et al. make a hash of this point. Early on, they give the conventional formula of total expected error as the sum of bias and variance (they don’t further decompose variance into irreducible error and ‘random’ error) with the aim of talking about the two separately, and naturally, never succeed in doing that.
The conceptual issues ought not detract us from the important point of the book. It is useful to think about human judgment systems as mathematical functions. We should expect the same inputs to map to the same output. It turns out that it isn’t even remotely true in most human decision-making systems. Take insurance underwriting, for instance. Given the same data (realistic but made-up information about cases), the median percentage difference between quotes between any pair of underwriters is an eye-watering 55% (which means that for half of the cases, it is worse than 55%), about five times as large as expected by the executives. There are a few interesting points that flow from this data. First, if you are a customer, your optimal strategy is to get multiple quotes. Second, what explains ignorance about the disagreement? There could be a few reasons. First, when people come across a quote from another underwriter, they may ‘anchor’ their estimate on the number they see, reducing the gap between the number and the counterfactual. Second, colleagues plausibly read to agree—less effort and optimizing for collegiality, asking, “Could this make sense?”, than read to evaluate, “Does this make sense?” (see my notes for a fuller set of potential explanations.)
Data from asylum reviews is yet starker. “A study of cases that were randomly allotted to different judges found that one judge admitted 5% of applicants, while another admitted 88%.” (Paper.)
Variability can stem from only two things. It could be that the data doesn’t allow for a unique judgment (irreducible error). (But even here, the final judgment should reflect the uncertainty in the data.) Or that at least one person is ‘wrong’ (has a different answer than others). Among other things, this can stem from:
variation in skill, e.g., how to assess patent applications
variation in effort, e.g., some people put more effort than others
agency and preferences, e.g., I am a conservative judge, and I can deny an asylum application because I have the power to do so
biases like using irrelevant information, e.g., weather, hypoglycemia, etc.
(Note: a lack of variability doesn’t mean we are on to the right answer.)
The list of proposed solutions is extensive—from selecting better judges to the wisdom of the crowds to using models to training people better to more elaborate schemes like dividing the decision task and asking people to make relative than absolute judgments. The evidence backing the solutions is not always hefty, which meshes with the ideolog-like approach to evidence present everywhere in the book. When I did a small audit of the citations, three things stood out (the overarching theme is adherence to the “No Congenial Result Scrutinized or Left Uncited Act”):
Extremely small n studies cited without qualification. Software engineers. Quote from the book: “when the same software developers were asked on two separate days to estimate the completion time for the same task, the hours they projected differed by 71%, on average.” The underlying paper: “In this paper, we report from an experiment where seven experienced software professionals estimated the same sixty software development tasks over a period of three months. Six of the sixty tasks were estimated twice.”
Extremely small n studies cited without qualification. Israeli Judges. Hypoglycemia and judgment: “Our data consist of 1,112 judicial rulings, collected over 50 d in a 10-mo period, by eight Jewish-Israeli judges (two females) who preside over two different parole boards that serve four major prisons in Israel.”
Surprising but likely unreplicable results. “When calories are on the left, consumers receive that information first and evidently think “a lot of calories!” or “not so many calories!” before they see the item. Their initial positive or negative reaction greatly affects their choices. By contrast, when people see the food item first, they apparently think “delicious!” or “not so great!” before they see the calorie label. Here again, their initial reaction greatly affects their choices. This hypothesis is supported by the authors’ finding that for Hebrew speakers, who read right to left, the calorie label has a significantly larger impact..” (Paper.) “We show that if the effect sizes in Dallas et al. (2019) are representative of the populations, a replication of the six studies (with the same sample sizes) has a probability of only 0.014 of producing uniformly significant outcomes.” (Paper.)
Citations to HBR. Citations to think pieces in Harvard Business Review (10 citations in total based on a keyword search) and books like ‘Work Rules!’ for a fair many claims.
Very little of the code that the government pays for is open-sourced. One of the reasons is that private companies would rather the code remain under wraps so that the errors never come to light, the price for producing software is never debated, and they get to continue to charge for similar work elsewhere.
Open-sourcing code is liable to produce the following benefits:
It will help us discover bugs.
It will reduce the cost of building similar software. In a federal system, many local agencies produce (or buy) similar software to help administer similar services. Having the code open-sourced is likely to reduce the barrier to entry for firms bidding to build such software and will likely lead to lower costs over time.
Freely available software under a generous license, e.g., queue management software, optimal staffing software, etc., benefits the economy as firms do not have to invest as much in building such systems.
It will likely increase trust in the government. For instance, where software is used to estimate benefits, the auditability of the software is likely to lead to a modest increase in confidence in the correctness of how the law has been translated into code.
There are at least three ways to open-sourcing government code. First, firms like OpenGov that produce open-source software for the government are already helping bring some of the code online. But given that the space for government software is large, it will likely take many decades for a tangible proportion of software to be open-sourced. Second, we can lobby the government to change the law so that companies (and agencies) are mandated to open source certain software they build for the government. But the prognosis is bleak, given that the government contractors are likely lobbying hard against it. The third option is to use FOIA to request code and make it available on Github. I sense that this is a tenable option.
Say that we want to measure how often people go to risky websites. Let’s assume that the measurement of risk is expensive. We have data on how often people visit each domain on the web from a large sample. The number of unique domains in the data is large, making measuring the population of domains impossible. Say there is a sharp skew in the visitation of domains. What is the fewest number of domains we need to measure to get s.e. of no greater than X per row?
Here are three ideas.
Base. Sample domains in each row (with replacement) in proportion to views/time to get to the desired s.e. Then, collate the selected domains and get labels for those.
Exploit the skew. For instance, sample from 99% of the distribution and save yourself from the long tail. Bound each estimate by the unsampled 1% (which could be anything) and enjoy. For greater accuracy, do a smaller, cruder sample of the 1% and get to the +/- 10% with an n = 100. The full version of this point is as follows: we benefit from increasing the probability of including more frequently occurring domains. Taken to the extremum, you could deterministically include the most frequent domains, and then prorate the size of the sample for the rest by the size of the area under the curve. This kind of strategy can help answer: how to optimally sample skewed distributions to get the smallest s.e. with the fewest observations?
Cheap measures. The base measurement strategy may be expensive but it may be possible to come up with a cheaper, less accurate measurement strategy that you can apply to the long tail. Validate (and calibrate) the results with the expensive coding strategy for a randomly selected sample of respondents.
In a new paper, Chohlas-Wood et al. present three interesting points:
Some of the major policing strategies have scant empirical support:
The impact of “pulling over drivers for minor traffic violations” (for the alleged purpose of “[preventing] criminal activity by intercepting individuals driving to and from the scene of a crime”) in Nashville was ~ 0 on serious crimes. (See Figures 1 and 2). To get a sense of the scale of the intervention: “In 2012, the MNPD conducted traffic stops up to ten times more frequently per capita than police departments in similar U.S. cities.”
The impact of stop and frisk in NYC on serious crime was also ~ 0. Again, to get a sense of the scale of the policy: “NYPD officers reported conducting nearly 700,000 Terry stops in 2011 alone, nearly 90% of which involved Black or Hispanic pedestrians.”
GS: None of this is terribly surprising. All over the world, very few policies are chosen as a result of careful data analysis. Why would policing be any different? My other prior based on looking at a fair bit of US crime data is that to a first approximation, all trends are national. When policing is local and trends are national, it suggests that the way policing is done is perhaps not the most important factor in preventing crime.
Racial bias in who is stopped:
“[A]t any given level of risk Black and Hispanic individuals were frisked considerably more often than white individuals.” (NYC, 2011-2012)
“[T]he rates at which frisks recover weapons are significantly lower for frisked Black individuals (3.8%) and Hispanic individuals (3.4%) compared to white individuals (5.7%).” (From the Chicago Police Department (CPD) in 2017)
GS: I am impressed by the contraband recovery rates. Either the base rate of ‘contraband’ is super high or the police is very good. My hunch is the former but would love to see data. (See below.)
GS: If police select who to stop based on observable characteristics (conditional on location; what else can they rely on?), criminals may be incentivized to game that reducing the value of observables over time.
Whack-a-mole nature of policing policies
“The settlement agreement with the ACLU took effect on January 1, 2016.85 For 2016, the CPD reported a total of approxi-mately 100,000 pedestrian stops, a sharp drop from the roughly 600,000 stops reported for 2015 (Figure 9).86 At the same time, the number of traffic stops made by the CPD began to rise. The CPD reported around 100,000 traffic stops in 2014 and a similar amount in 2015, but by 2019, the CPD reported nearly 600,000 traffic stops, with large increases occurring each year from 2016 to 2019. These traffic stops came to closely resemble the pedestrian stops that the CPD was contemporaneously under pressure to curtail. …”
Following a consent decree and settlement in 2011, pedestrian stops fell from more than 200,000 reported stops in 2014 (the earliest year for which we have data released publicly by the city) to fewer than 100,000 reported stops in each of 2018 and 2019, while traffic stops almost doubled in the same period”
“Back in the 1990s, it looked like the Supreme Court was going to run drug checkpoints, so Indianapolis started doing one. Drivers were stopped completely at random until the Supreme Court put an end to it.
“The city conducted six such roadblocks between August and November that year, stopping 1,161 vehicles and arresting 104 motorists. Fifty-five arrests were for drug-related crimes, while 49 were for offenses unrelated to drugs. The overall “hit rate” of the program was thus approximately nine percent.”
If you take this as a baseline, police are twice as good at finding contraband as random selection. If “contraband” just means drugs, then probably four times as good. So the baseline rate of contraband is high (a surprising number of people have warrants, drugs, and weapons) but police are also beating the odds.”
Chicago is not Indianapolis and 2015 is not 2000 but still valuable.
p.p.s. Graham also highlights an issue with Figure 2. Chohlas-Wood et al. plot the murder rate per 1k on the same graphs as vehicle stops per 1k. This naturally squishes the variation in the murder rate. The general rule is that you should avoid plotting variables that vary by orders of magnitude on the same graph. At any rate, doing so gives the appearance that the authors are putting a thumb on the scale.
In an influential essay, The Cognitive Style of PowerPoint, Tufte argues that (PowerPoint) presentations are unsuitable for serious problems. The essay is largely polemical, with Tufte freely mixing points about affordances of the medium with criticisms of bad presentations and lazy broadsides.
Hilarious stuff first:
“All 3 reports have standard PP format problems: elaborate bullet outlines; segregation of words and numbers (12 of 14 slides with quantitative data have no accompanying analysis); atrocious typography; data imprisoned in tables by thick nets of spreadsheet grids; only 10 to 20 short lines of text per slide.”
“On this single Columbia slide, in a PowerPoint festival of bureaucratic hyper-rationalism, 6 different levels of hierarchy are used to classify, prioritize, and display 11 simple sentences”
“In 28 books on PP presentations, the 217 data graphics depict an average of 12 numbers each. Compared to the worldwide publications shown in the table at right, the statistical graphics based on PP templates are the thinnest of all, except for those in Pravda back in 1982, when that newspaper operated as the major propaganda instrument of the Soviet communist party and a totalitarian government.”
In the essay, I could only rescue two points about affordances (that I buy):
“When information is stacked in time, it is difficult to understand context and evaluate relationships.”
Inefficiency: “A talk, which proceeds at a pace of 100 to 160 spoken words per minute, is not an especially high resolution method of data transmission. Rates of transmitting visual evidence can be far higher. … People read 300 to 1,000 printed words a minute, and find their way around a printed map or a 35mm slide displaying 5 to 40 MB in the visual field. Yet, in a strange reversal, nearly all PowerPoint slides that accompany talks have much lower rates of information transmission than the talk itself. As shown in this table, the PowerPoint slide typically shows 40 words, which is about 8 seconds worth of silent reading material. The slides in PP textbooks are particularly disturbing: in 28 textbooks, which should use only first-rate examples, the median number of words per slide is 15, worthy of billboards, about 3 or 4 seconds of silent reading material. This poverty of content has several sources. First, the PP design style, which typically uses only about 30% to 40% of the space available on a slide to show unique content, with all remaining space devoted to Phluff, bullets, frames, and branding. Second, the slide projection of text, which requires very large type so the audience can read the words.”
From Working Backwards, which cites the article as the reason Amazon pivoted from presentations to 6-pagers for its S-team meetings, there is one more reasonable point about presentations more generally:
“…the public speaking skills of the presenter, and the graphics arts expertise behind their slide deck, have an undue—and highly variable—effect on how well their ideas are understood.”
Working Backwards
The points about graphics arts expertise, etc., apply to all documents but are likely less true for reports than presentations. (It would be great to test the effect of the prettiness of graphics on their persuasiveness.)
Reading the essay made me think harder about why we use presentations in meetings about complex topics more generally. For instance, academics frequently present to other academics. Replacing presentations with 6-pagers that people quietly read and comment on at the start of the meeting and then discuss may yield higher quality comments and better discussion and better evaluation of the scholar (and the scholarship).
A recent piece on ESPNCricinfo analyses the DRS data and argues that cricket should do away with neutral umpires. I reanalyzed the data.
If a game is officiated by a home umpire, we expect the following:
Hosts will appeal less often as they are likely to be happier with the decision in the first place
When visitors appeal a decision, their success rate should be higher than the hosts. Visitors are appealing against an unfavorable call—a visiting player was unfairly given out or they felt the host player was unfairly given not out. And we expect the visitors to get more bad calls.
When analyzing success rate, I think it is best to ignore appeals that are struck down because they defer to the umpire’s call. Umpire’s call generally applies to LBW decisions, and especially two aspects of the LBW decision: 1. whether the ball was pitching in line, 2. whether it was hitting the wickets. To take a recent example, in the second test of the 2021 Ashes series, Lyon got a wicket when the impact was ‘umpire’s call’ and Stuard Broad was denied a wicket for the same reason.
Ollie Robinson Unsuccessfully Challenging the LBW Decision
Stuart Broad Unsuccessfully Challenging the Not-LBW Decision
With the preliminaries over, let’s get to the data covered in the article. Table 1 provides some summary statistics of the outcomes of DRS. As is clear, the visiting team appealed the umpire’s decision far more often than the home team: 303 vs. 264. Put another way, the visiting team lodged nearly one more appeal per test than the home team. So how often did the appeals succeed? In line with our hypothesis, the home team appeals were upheld less often (24%) than visiting team’s appeals (29%).
Table 1.Review Outcomes Under Home Umpires. 41 Tests. July 2020–Nov. 2021.
It could be the case that these results are a consequence of something to do with host vs. visitor than home umpires. For instance, hosts win a lot, and that generally means that they will bowl for shorter periods of time and bat for longer periods of time. We account for this by comparing outcomes under neutral umpires. The article has data on the same. There, you see that the visiting team makes fewer appeals (198) than the home team (214). And the visiting team’s success rate in appeals is slightly lower (29%) than the home team’s rate (30%).
p.s.
At the bottom of the article is another table that breaks down reviews by host country:
HOST COUNTRY
TESTS
UMPIRES
REVIEWS
HOSTS’ SUCCESS (%)
VISITORS’ SUCCESS (%)
ENGLAND
13
AG WHARF, MA GOUGH*, RA KETTLEBOROUGH*, RK ILLINGWORTH*
190
22/85 (26%)
32/105 (30%)
NEW ZEALAND
4
CB GAFFANEY*, CM BROWN, WR KNIGHTS
41
3/17 (18%)
5/24 (21%)
AUSTRALIA
4
BNJ OXENFORD, P WILSON, PR REIFFEL*
55
5/30 (17%)
6/25 (24%)
SOUTH AFRICA
2
AT HOLDSTOCK, M ERASMUS*
20
2/10 (20%)
3/10 (30%)
SRI LANKA
6
HDPK DHARMASENA*, RSA PALLIYAGURUGE
85
9/42 (21%)
13/43 (30%)
PAKISTAN
2
AHSAN RAZA, ALEEM DAR*
27
0/11 (0%)
6/16 (38%)
INDIA
5
AK CHAUDHARY, NITIN MENON*, VK SHARMA
87
9/40 (23%)
11/47 (23%)
WEST INDIES
6
GO BRATHWAITE, JS WILSON*
94
13/50 (26%)
13/44 (29%)
Data from ESPNCricinfo
But the data doesn’t match the one in the table above. For one, the number of tests considered is 42 than 41. For two, and perhaps relatedly, the total number of reviews is 599 than 567. To be comprehensive, let’s do the same calculations as above. The visiting team appeals more (314) than the host team (285). The host team success rate is 22% (63/285), and the visiting team success rate is 28% (89/314). If you were to do a statistical test for success rates:
prop.test(x = c(63, 89), n = c(285, 314))
2-sample test for equality of proportions with continuity correction
data: c(63, 89) out of c(285, 314)
X-squared = 2.7501, df = 1, p-value = 0.09725
alternative hypothesis: two.sided
95 percent confidence interval:
-0.13505623 0.01028251
sample estimates:
prop 1 prop 2
0.2210526 0.2834395
The KNN classifier is one of the most intuitive ML algorithms. It predicts class by polling k nearest neighbors. Because it seems so simple, it is easy to miss a couple of the finer points:
Sample Splitting: Traditionally, when we split the sample, there is no peeking across samples. For instance, when we split the sample between a train and test set, we cannot look at the data in the training set when predicting the label for a point in the test set. In knn, this segregation is not observed. Say we partition the training data to learn the optimal k. When predicting a point in the validation set, we must pass the entire training set. Passing the points in the validation set would be bad because then the optimal k will always be 0. (If you ignore k = 0, you can pass the rest of the dataset.)
Implementation Differences: “Regarding the Nearest Neighbors algorithms, if it is found that two neighbors, neighbor k+1 and k, have identical distances but different labels, the results will depend on the ordering of the training data.” (see here; emphasis mine.)
This matters when the distance metric is discrete, e.g., if you use an edit-distance metric to compare strings. Worse, scikit-learn doesn’t warn users during analysis.
In R, one popular implementation of KNN is in a package called class. (Overloading the word class seems like a bad idea but that’s for a separate thread.) In class, how the function deals with this scenario is decided by an explicit option: “If [the option is] true, all distances equal to the kth largest are included. If [the option is] false, a random selection of distances equal to the kth is chosen to use exactly k neighbours.”
For the underlying problem, there isn’t one clear winning solution. One way to solve the problem is to move from knn to adaptive knn: include all points that are as far away as the kth point. This is what class in R does when the option all.equal is set to True. Another solution is to never change the order in which the data are accessed and to make the order as part of how the model is exported.
Say that there is a donation solicitation company. Say that there are 100M potential donors they can reach out to eachyear. Let’s also assume that the company gets paid on a contingency fee basis, getting a fixed percentage of all donations.
The company currently follows the following process: it selects 10M potential donors from the list using some rules and reaches out to them. The company gets donations from 2M donors. Also, assume that agents earn a fixed percentage of the dough they bring in.
What’s profit-maximizing staffing?
The company’s optimal strategy for staffing (depending on the risk preference) is:
where reflects the probability of donation from potential donor , is the value of the donation from the ith customer, is the contingency fee, and is the cost of reaching out to the potential donor.
Modeling can be challenging because the cost may be a function of donor attributes but also the granularity at which you can purchase labor, the need for specialists for soliciting donations from different potential donors, e.g., language, etc. For instance, classically, it may well be that you can only buy labor in chunks, e.g., full-time workers for some time. We leave these considerations out for now. We also take as fixed the optimal strategy to reach out to each donor.)
The data we have the greatest confidence in pertains to cases where we tried and observed an outcome. The data for the 10M can look like this:
We can use this data to learn a regression within the 10M and then use the model to predict the rank. If you use the model to rank the 10M you get next year, you can get greater profits from not pursuing the 8M. If you use it to rank the remaining 90M, you are making the assumption that donors who were not selected but are otherwise similar to those who were chosen, are similar in their returns. It is likely not the case.
To get better traction on the 90M, you need to get new data, starting with a random sample, and using deep reinforcement learning to figure out the kind of donors who are profitable to reach out to.










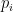 reflects the probability of donation from potential donor
reflects the probability of donation from potential donor  ,
, 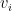 is the value of the donation from the ith customer,
is the value of the donation from the ith customer,  is the contingency fee, and
is the contingency fee, and 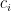 is the cost of reaching out to the potential donor.
is the cost of reaching out to the potential donor.