The first part of the series, “Improving and Deploying On-Device Models With Confidence,” is posted here. The second part, “Keeping Track of Changes,” is posted here.
With Atul Dhingra
For a broad class of machine learning problems, nitpicking over the neural net architecture is over (see, for instance, here). Instead, the focus has shifted to data. In the note below, we articulate some ways of thinking about what data to collect. In our discussion, we focus on supervised learning.
The answer to “What data to collect?” varies by where you are in the product life cycle. If you are building a new ML product and the aim is to deploy something (basic) that delivers value and then iterate on it, one answer to the question is to label easy-to-predict cases—cases that allow you to build models where the precision is high but the recall is low. The bar is whether the model can do as well as business as usual for a small set of cases. The good thing is that you can hurdle that bar another way—by coding a random sample, building a model, and choosing a threshold where the precision is greater than business as usual (read more here). For producing POCs, models built on cheap data, e.g., open-source data, which plausibly do not produce value, can also “work” though they need to be managed against the threat of poor performance reducing faith in the system.
The more conventional case is where you have a deployed model, and you want to improve its performance. There the answer to what data to collect is data that yields the highest ROI. (The answer to what data provides the highest ROI will vary over time, so we need a system that continuously answers it.) If we assume that the labeling costs for points are the same, the prioritization function reduces to ranking data by returns. To begin with, let’s assume that returns are measured by the function specified by the cost function. So, for instance, if we are looking for a model that lowers the RMSE, we would like to rank by how much reduction in RMSE we get from labeling an additional point. And naturally, we care about the test set RMSE. (You can generalize this intuition to any loss function.) So far, so good. The rub comes from the fact that there is no trivial answer to the problem.
One way to answer the question is to run experiments, sampling across Xs, or plausibly use bandits and navigate the explore-exploit tradeoff smartly. Rather than do experiments, you can also exploit the data you have to figure out the kinds of points that make the most impact on RMSE. One way to get at that is using influence functions. There are, however, a couple of challenges in using these methods. The first is that the covariate space is large and the marginal impact is small, and that means inference is noisy. The second is a more general problem. Say you find that X_1, X_2, X_3, … are the points that lead to the largest reduction in RMSE. But how do you use that knowledge to convert it into a data collection problem? Is it that we should collect replicas of X_1? Probably not. We need to generalize from these examples and come up with a statement about the “type of data” that needs to be collected, e.g., more images where the traffic sign is covered by trees. To come up with the ‘type’, we need to specify what the example is not—how does it differ from the rest of the data we have? There are a couple of ways to answer the question. The first is to use clustering (using embeddings) and then assigning someone to label the clusters. Another is to use supervised learning to classify the X_1, X_2, X_3 from the rest of the data and figure out the “important predictors.”
There are other answers to the question, “What data to collect?” For instance, we could look to label points where we are least certain or where we make the largest error. The intuition in the classification setting is that these points are closest to the hyperplane that separates the classes, and if you can learn to classify near the boundary, you are set. In using this method, you can also sometimes discover mislabeling. (The RMSE method we talk about above doesn’t interrogate the Y, taking the labels as given.)
Another way to answer the question is to use model interpretation tools to figure out “why” the models are making errors. For instance, you could find that the reason why the model is making errors is because of confounding. Famously, for instance, a cat vs. dog classifier can merely be an outdoor vs. indoor classifier. And if we see the model using confounding features like the background in consideration, we could a) better label the data to segment out dogs and cats from the background, b) introduce paired examples such that the only thing different between any two images is strictly presence or absence of a dog/cat.







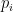 reflects the probability of donation from potential donor
reflects the probability of donation from potential donor  ,
, 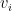 is the value of the donation from the ith customer,
is the value of the donation from the ith customer,  is the contingency fee, and
is the contingency fee, and 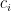 is the cost of reaching out to the potential donor.
is the cost of reaching out to the potential donor.