Equity is an integral part of start-up compensation. However, employees and employers may disagree about the value of equity. Employers, for instance, may value equity higher than potential employees because they have access to better data or simply because they are more optimistic. One consequence of the disagreement between potential employees’ and employers’ valuations of equity is that some salary negotiations may fail. In the particular scenario that I highlightabove, one way out of the quandary may be to endow an employee with options commensurate with their lower valuation and have a buy-back clause if the employer’s prediction pans out (when the company is valued in the next round or during exit). Another way to interpret this particular trade is as trading risk for a cap on the upside. Thus, this kind of strategy may also be useful where employees are more risk-averse than employers.
Booking travel online feels like shopping in an Indian bazaar: a deluge of options, no credible information, aggressive hawkers (“recommendations” and “targeted ads”), and hours of frantic search that ends with purchasing something more out of exhaustion than conviction. Online travel booking is not unique in offering this miserable experience. Buying on Amazon feels like a similar sand trap. But why is that? Poor product management? A more provocative but perhaps more accurate answer is that the product experience, largely unchanged or becoming worse in the case of Amazon, is “optimal.” Many people enjoy the “hunt.” They love spending hours on end looking for a deal, comparing features, and collecting and interpreting wisps of information. To satiate this need, the “optimal” UI for a market may well be what you see on Amazon or travel booking sites. The lack of trustworthy information is a feature, not a bug.
The point applies more broadly. A range of products have features that have no other purpose than gaming behavioral concerns. Remember the spinning wheel on your tax preparation software as the software looks for all the opportunities to save you money? That travesty is in the service of convincing users that the software is ‘working hard.’ Take another example. Many cake mixes sold today require you to add an egg. That ruse was invented to give housewives (primarily the ones who were cooking say 50 years ago) the feeling that they were cooking. One more. The permanent “sales” at Macy’s and at your local grocery store mean that everyone walks out feeling like a winner. And that means a greater likelihood of you coming back again.
p.s. When the users don’t trust the website, the utility of recommendations in improving consumer surplus ~ 0 among sophisticated users.
Stories abound about unqualified people getting admitted to highly selective places because of quotas. But the chances are that these are merely stories with no basis in fact. If an institution is highly selective and if the number of applicants is sufficiently large, quotas are unlikely to lead to people with dramatically lower abilities being admitted even when there are dramatic differences across groups. Relatedly, it is unlikely to have much of an impact on the average ability of the admitted cohort. If the point wasn’t obvious enough, it would be after the following simulation. Say the mean IQ of the groups differs by 1 s.d. (which is the difference between Black and White IQ in the US). Say that the admitting institution only takes 1000 people. In the no-quota regime, the top 1000 people get admitted. In the quota regime, 20% of the seats are reserved for the second group. With this framework, we can compare the IQ of the last admitee across the conditions. And the mean ability.
# Set seed for reproducibility
set.seed(123)
# Simulate two standard normal distributions
group1 <- rnorm(1000000, mean = 0, sd = 1) # Group 1
group2 <- rnorm(1000000, mean = -1, sd = 1) # Group 2, mean 1 sd lower than Group 1
# Combine into a dataframe with a column identifying the groups
data <- data.frame(
value = c(group1, group2),
group = rep(c("Group 1", "Group 2"), each = 1000000)
)
# Pick top 800 values from Group 1 and top 200 values from Group 2
top_800_group1 <- head(sort(data$value[data$group == "Group 1"], decreasing = TRUE), 800)
top_200_group2 <- head(sort(data$value[data$group == "Group 2"], decreasing = TRUE), 200)
# Combine the selected values and estimate the mean
combined_top_1000 <- c(top_800_group1, top_200_group2)
# IQ of the last five admitees
round(tail(head(sort(data$value, decreasing = TRUE), 1000)), 2)
[1] 3.11 3.11 3.10 3.10 3.10 3.10
round(tail(combined_top_1000), 2)
[1] 2.57 2.57 2.57 2.57 2.56 2.56
# Means
round(mean(head(sort(data$value, decreasing = TRUE), 1000)), 2)
[1] 3.37
round(mean(combined_top_1000), 2)
[1] 3.31
# How many people in top 1000 from Group 2 in no-quota?
sorted_data <- data[order(data$value, decreasing = TRUE), ]
top_1000 <- head(sorted_data, 1000)
sum(top_1000$group == "Group 2")
[1] 22
Under no-quota, the person with the least ability who is admitted is 3.1 s.d. above the mean while under quota, the person with the least ability who is admitted is 2.56 s.d. above the mean. The mean ability of the admitted cohort is virtually indistinguishable—3.37 and 3.31 for the no-quota and quota conditions respectively. Not to put too fine a point—the claim that quotas lead to gross misallocation of limited resources is likely grossly wrong. This isn’t to say there isn’t a rub. With a 1 s.d. difference, the representation in the tails is grossly skewed. Without quota, there would be just 22 people from Group 2 in the top 1000. So 178 people from Group 1 get bumped. This point about fairness is perhaps best thought of in context of how much harm comes to those denied admission. Assuming enough supply across the range of selectivity—this is approximately true for the U.S. for higher education with a range of colleges at various levels of selectivity—it is likely the case that those denied admission at more exclusive institutions get admitted at slightly lower ranked institutions and do nearly as well as they would have had they been admitted to more exclusive institutions. (See Dale and Kreuger, etc.).
p.s. In countries like India, 25 years ago, there was fairly limited supply at the top and large discontinuous jumps. Post liberalization of the education sector, this is likely no longer true.
p.p.s. What explains the large racial gap in SAT scores of the admittees to Harvard? It is likely that it is founded in Harvard weighing factors such as athletic performance in admission decisions.
There are a few different options for buying time with industry experts, e.g., https://officehours.com/, https://intro.co/, etc. However, there is no marketplace for buying academics’ time. Some surplus is likely lost as a result. For one, some academics want advice on what they write. To get advice, they have three choices—academic friends, reviewers, or interested academics at conferences or talks. All three have their problems. Or they have to resort to informal markets like Kahneman.
“He called a young psychologist he knew well and asked him to find four experts in the field of judgment and decision-making, and offer them $2,000 each to read his book and tell him if he should quit writing it. “I wanted to know, basically, whether it would destroy my reputation,” he says. He wanted his reviewers to remain anonymous, so they might trash his book without fear of retribution.”
For what it’s worth, Kahneman’s book still had major errors. And that may be the point. Had he access to a better market, with ratings on the ability to review quantitative material, he may not have had the errors. A fully fleshed market could offer options to workers to price discriminate based on whether the author is a graduate student or a tenured professor at a top-ranked private university. Such a market may also prove a useful revenue stream for academics with time and talent who want additional money.
Reviewing is but one example. Advice on navigating the academic job market, research design, etc., can all be sold.
Recommendation systems paint a wonderful picture: The system automatically gets to know you and caters to your preferences. And that is indeed what happens except that the picture is warped. Warping happens for three reasons. The first is that humans want more than immediate gratification. However, the systems are designed to learn from signals that track behaviors in an environment with strong temptation and mostly learn “System 1 preferences.” The second reason is use of the wrong proxy metric. One common objective function (on content aggregation platforms like YouTube, etc.) is to maximize customer retention (a surrogate for revenue and profits). (It is likely that the objective function doesn’t vary between subscribers and ad-based tier.) And the conventional proxy for retention is time spent on a product. It doesn’t matter much how you achieve that; the easiest way is to sell Fentanyl. The third problem is the lack of good data. Conventionally, the choices of people whose judgment I trust (and the set of people whose judgments these people trust) are a great signal. But they do not make it directly into recommendations on platforms like YouTube, Netflix, etc. Worse, recommendations based on similarity in consumption don’t work as well because of the first point. And recommendations based on the likelihood of watching often reduce to recommending the most addictive content.
Solutions
More Control. To resist temptation, humans plan ahead, e.g., don’t stock sugary snacks at home. By changing the environment, humans can more safely navigate the space during times when impulse control is weaker.
Rules. Let people write rules for the kinds of video they don’t want to be offered.
Source filtering. On X (formerly Twitter), for instance, you can curate your feed by choosing who to follow. (X has ‘For You’ and ‘Following’ tabs.) The user only sees tweets that the users they follow tweet or retweet. (On YouTube, you can subscribe to channels but the user sees more than the content produced by the channels they subscribe to.)
Time limits. Let people set time limits (for certain kinds of content).
Profiles Offer a way to switch between profiles.
Better Data
Get System 2 Data. Get feedback on what people have viewed at a later time. For instance, in the history view, allow people to score their viewing history.
Network data. Only get content from people whose judgment you trust. This is different from #1a, which proposes allowing filtering on content producers.
Information. Provide daily/weekly/monthly report cards on how much time was spent watching what kind of content, and what times of the day/week were where the person respected their self-recorded preferences (longer-term).
Storefronts. Let there be a marketplace of curation services (curators). And let people visit the ‘store’ than the warehouse (and a particular version of curation).
Acknowledgment. The article benefitted from discussion with Chris Alexiuk and Brian Whetter.
Many times within a narrow product category like breakfast cereals, ice cream tubs, etc., the prices of different varieties within a brand are the same. The same pattern continues in many ice cream stores where you are charged for the quantity instead of the flavor or the vessel in which ice cream is served. It is unlikely that input costs are the same across varieties. So what explains it? It could be that the prices are the same because the differences in production costs are negligible. Or it could be that retailers opt for uniform pricing because of managerial overhead (see also this paper). Or there could be behavioral reasons. Consumers may shop in a price-conscious manner if the prices are different and may buy less.
Breakfast cereals have another nuance. As you can see in the graphic above, the weight of the ‘family size’ box (which has the same size and shape) varies. It may be because there are strong incentives to keep the box size the same. This in turn may be because of stocking convenience or behavioral reasons, e.g., consumers may think they are judging between commensurate goods if the boxes are the same size. (It could also be that consumers pay for volume not weight.)
Consider the following scenario: There are multiple firms looking to fill identical jobs. And there are multiple eligible workers given each job opening. Both the company and the workers have perfect information, which they are able toacquire without cost. Assume also that employees can switch jobs without cost. Under these conditions, it is expensive for employers to discriminate. If company A prejudicially excludes workers from Group X, company B can hire the same workers at a lower rate (given that the demand for them is lower) and outcompete company A. It thus reasons thatdiscrimination is expensive. Some people argue that for the above reasons, we do not need anti-discrimination policies.
There is a crucial, well-known, but increasingly under-discussed nuance to the above scenario. When consumers or co-workers also discriminate, it may be profit-maximizing for a firm to discriminate. And the point fits the reality of 60 years ago when many hiring ads specifically banned African Americans from applying (‘Whites only’, ‘Jews/Blacks need not apply’, etc.), many jobs had dual wage scales, and explicitly segregated job categories existed. A similar point applies to apartment rentals. If renters discriminate by the race of the resident, the optimal strategy for an apartment block owner is to discriminate by race. Indian restaurants provide another example. If people prefer Brahmin cooks (for instance, see here, here, and here), the profit-maximizing strategy for restaurants is to look for Brahmin cooks (for instance, see here). All of this is to say that under these conditions, you can’t leave it to the markets to stop discrimination.
Many widely used machine-learning models rely on copyrighted data. For instance, Google finds the most relevant web pages for a search term by relying on a machine learning model trained on copyrighted web data. But the use of copyrighted data by machine learning models that generate content (or give answers to search queries than link to sites with the answers) poses new (reasonable) questions about fair use. By not sharing the proceeds, such systems also kill the incentives to produce original content on which they rely. For instance, if we don’t incentivize content producers, e.g., people who respond to Stack Overflow questions, the ability of these models to answer questions in new areas is likely to be lower. The concern about fair use can be addressed by training on data from content producers that have opted to share their data. The second problem is more challenging. How do you build a system that shares proceeds with content producers?
One solution is licensing. Either each content creator licenses data independently or becomes part of a consortium that licenses data in bulk and shares the proceeds. (Indeed Reddit, SO, etc. are exploring this model though they have yet to figure out how to reward creators.) Individual licensing is unlikely to work at scale so let’s interrogate the latter. One way the consortium could work is by sharing the license fee equally among the creators, perhaps pro-rated by the number of items. But such a system can easily be gamed. Creators merely need to add a lot of low-quality content to bump up their payout. And I expect new ‘creators’ to flood the system. In equilibrium, it will lead to two bad outcomes: 1. An overwhelming majority of the content is junk. 2. Nobody is getting paid much.
The consortium could solve the problem by limiting what gets uploaded but it is expensive to do. Another way to solve the problem is by incentivizing at a person-item level. There are two parts to this—establishing what was used and how much and pro-rating the payouts by value. To establish what item was used in what quantity, we may want a system that estimates how similar the generated content is to the underlying items. (This is an unsolved problem.) The payout would be prorated by similarity. But that may not incentivize creators who value their content a lot, e.g., Drake, to be part of the pool. One answer to that is to craft specialized licensing agreements as is commonly done by streamlining platforms. Another option would be to price the contribution. One way to price the contribution would be to generate counterfactuals (remove an artist) and price them in a marketplace. But it is possible to imagine that there is natural diversity in what is created and you can model the marginal contribution of an artist. The marketplace analogy is flawed because there is no one marketplace. So the likely way out is for all major marketplaces to subscribe to some credit allocation system.
Money is but one reason why people produce. Another reason people produce content is so that they can get rewarded for their reputations, e.g., SO. Generative systems built on these data however have not been implemented in a way to keep these markets intact. The current systems reduce traffic and do not give credit to the people whose answers they learn from. The result is that developers have less of an incentive to post to SO. And SO licensing its content doesn’t solve this problem. Directly tying generative models to user reputations is hard partly because generative models are probabilistically mixing things and may not produce the right answer but if the signal is directionally correct, it could be fed back to reputation scores of creators.
Hardly a day passes without a major company announcing the release of a new scientific paper or code around a powerful technique. But why do so many companies open source (via papers and code) so many impactful technologies almost as soon as they are invented? The traditional answers—to attract talent, and to generate hype—are not compelling. Let’s start with the size of the pie. Stability AI, based solely on an open-source model quickly raised money at a valuation of $1B. Assuming valuations bake in competitors, lots of money was left on the table in this one case. Next, come to the credit side — literally. What is the value of headlines (credit) during a news cycle, which usually lasts less than a day? As for talent, the price for the pain of not publishing ought not to be that high. And the peculiar thing is that not all companies seem to ooze valuable IP. For instance, prominent technology companies like Apple, Amazon, Netflix, etc. don’t ooze much at all. All that suggests that this is a consequence of poor management. But let’s assume for a second that the tendency was ubiquitous. There could be three reasons for it. First, it could be the case that companies are open-sourcing things they know others will release tomorrow to undercut others or to call dibs on the hype cycle. Another reason could be that they release things for the developer ecosystem on their platform. Except, this just happens not to be true. Another plausible answer is that when technology moves at a really fast pace — what is hard today is easy tomorrow— the window for monetization is small and companies forfeit these small benefits and just skim the hype. (But then, why invest in it in the first place?)
Say that people can be easily identified by characteristic C. Say that the average tip left by people of group C_A is smaller than !C_A with a wide variance in tipped amounts within each group. Let’s assume that the quality of service (two levels: high or low) is pro-rated by the expected tip amount. Let’s assume that the tip left by a customer is explained by the quality of service. And let’s also assume that the expected tip amount from C_A is low enough to motivate low-quality service. The tip is provided after the service. Assume no-repeat visitation. The optimal strategy for the customer is to not tip. But the service provider notices the departure from rationality from customers and serves accordingly. If the server had complete information about what each person would tip, then the service would be perfectly calibrated by the tipped amount. However, the server can only rely on crude surface cues, like C, and estimate the expected value of the tip. Given that, the optimal strategy for the server is to provide low-quality service to C_A, which would lead to a negative spiral.
It used to be that retail prices of generic products like coffee mugs, soap, etc., moved slowly. Not anymore. On major web retailers like Amazon, for a range of generic household products, the variation in prices over short periods of time is immense. For instance, on 12-Piece Porcelain, 12 Oz. Coffee Mug Set, the price ranged between $20.50 and $35.71 over the last year or so, with a hefty day-to-day variation.
On PCPartPicker, the variation in prices for Samsung SSD is equally impressive. Prices zig-zag on multiple sites (e.g., Dell, Adorama) by $100 over a matter of days multiple times over the last six months. (The cross-site variation—price dispersion—at a particular point in time is also impressive.)
What explains the within-site over-time variation? One reason could be supply and demand. There are three reasons I am skeptical of the explanation. First, on Amazon, the third-party new item price time series and Amazon price time series do not appear to be correlated (statistics by informal inspection or as one of my statistics professors used to call it—the ocular distortion test—so caveat emptor). On PCPartPicker, you see much the same thing: the cross-retailer price time series frequently crossover. Second, related to the first point, we should see a strong correlation in overtime price curves across substitutes. We do not. Third, the demand for generic household products should be readily forecastable, and the optimal dry good storage strategy is likely not storing just enough. Further, I am skeptical of strong non-linearities in the marginal cost of furnishing an item that is not in the inventory—much of it should be easily replenishable.
The other explanation is price exploration, with Amazon continuously exploring the profit-maximizing price. But this is also unpersuasive. The range over which the prices vary over short periods of time is too large, especially given substitutes and absent collusion. Presumably, companies have thought about the negative consequences of such wide price exploration bands. For instance, you cannot build a reputation as the ‘cheapest’ (unless there is coordination or structural reason for prices to move together.)
So I come empty when it comes to explanations. There is the crazy algorithm theory—as inventory dwindles, Amazon really hikes the price, and when it sees no sales, it brings the price right back down. It may explain the frequent sharp movements over a fixed band that you see in some places but plausibly doesn’t explain a lot of the other patterns we see.
Forget the explanations and let’s engage with the empirical fact. My hunch is that customers are unaware of the striking variation in the prices of many goods. Second, if customers become aware of this, their optimal strategy would be to use sites like CamelCamelCamel or PCPartPicker to pick the optimal time for purchasing a good. If retailers are somehow varying prices to explore profit-maximizing pricing (minus price discrimination based on location, etc.), and if all customers adopt the strategy of timing the purchase, then, in equilibrium, the retailer strategy would reduce to constant pricing.
p.s. I found it funny that there are ‘used product’ listings for soap.
p.p.s. I wrote about the puzzle of price dispersion on Amazon here.
In particular, in 521 villages in Haryana, we provided information on monthly immunization camps to either randomly selected individuals (in some villages) or to individuals nominated by villagers as people who would be good at transmitting information (in other villages). We find that the number of children vaccinated every month is 22% higher in villages in which nominees received the information.
The buildings, which are social units, were randomized to (1) targeting 20% of the women at random, (2) targeting friends of such randomly chosen women, (3) targeting pairs of people composed of randomly chosen women and a friend, or (4) no targeting. Both targeting algorithms, friendship nomination and pair targeting, enhanced adoption of a public health intervention related to the use of iron-fortified salt for anemia.
Coupon redemption reports showed that unadjusted adoption rates were 13.6% (SE = 1.5%) in the friend-targeted clusters, 11.2% (SE = 1.4%) in pair-targeted clusters, 9.1% (SE = 1.3%) in the randomly targeted clusters, and 0% in the control clusters receiving no intervention.
Targeting “structurally influential individuals,” e.g., people with lots of friends, people who are well regarded, etc., can lead to larger returns per ‘contact.’ This can be a useful thing. And as the studies demonstrate, finding these influential people is not hard—just ask a few people. There are, however, a few concerns:
One of the concerns with any targeting strategy is that it can change who is treated. When you use network-based targeting, it biases the treated sample toward those who are more connected. That could be a good thing, especially if returns are the highest on those with the most friends, like in the case of curbing contagious diseases, or it could be a bad thing if the returns are the greatest on the least connected people. The more general point here is that most ROI calculations for network targeting have only accounted for costs of contact and assumed the benefits to be either constant or increasing in network size. One can easily rectify this by specifying the ROI function more fully or adding “fairness” or some kind of balance as a constraint.
There is some stochasticity that stems from which person is targeted, and their idiosyncratic impact needs to be baked into standard error calculations for the ‘treatment,’ which is the joint of whatever the experimenters are doing and what the individual chooses to do with the experimenter’s directions (compliance needs a more careful definition). Interventions with targeting are liable to have thus more variable effects than without targeting and plausibly need to be reproduced more often before they used as policy.
The phrase “noise in decision making” brings to mind “random” error. Scientists, however, shy away from random error. Science is mostly about systematic error, except, perhaps, quantum physics. So Kahneman et al. conceive of noise as seemingly random error that is a result of unmeasured biases. For instance, research suggests that heat causes bad mood. And bad mood may, in turn, cause people to judge more harshly. If this were to hold, the variability in judging stemming from the weather can end up being interpreted as noise. But, as is clear, there is no “random” error, merely bias. Kahneman et al. make a hash of this point. Early on, they give the conventional formula of total expected error as the sum of bias and variance (they don’t further decompose variance into irreducible error and ‘random’ error) with the aim of talking about the two separately, and naturally, never succeed in doing that.
The conceptual issues ought not detract us from the important point of the book. It is useful to think about human judgment systems as mathematical functions. We should expect the same inputs to map to the same output. It turns out that it isn’t even remotely true in most human decision-making systems. Take insurance underwriting, for instance. Given the same data (realistic but made-up information about cases), the median percentage difference between quotes between any pair of underwriters is an eye-watering 55% (which means that for half of the cases, it is worse than 55%), about five times as large as expected by the executives. There are a few interesting points that flow from this data. First, if you are a customer, your optimal strategy is to get multiple quotes. Second, what explains ignorance about the disagreement? There could be a few reasons. First, when people come across a quote from another underwriter, they may ‘anchor’ their estimate on the number they see, reducing the gap between the number and the counterfactual. Second, colleagues plausibly read to agree—less effort and optimizing for collegiality, asking, “Could this make sense?”, than read to evaluate, “Does this make sense?” (see my notes for a fuller set of potential explanations.)
Data from asylum reviews is yet starker. “A study of cases that were randomly allotted to different judges found that one judge admitted 5% of applicants, while another admitted 88%.” (Paper.)
Variability can stem from only two things. It could be that the data doesn’t allow for a unique judgment (irreducible error). (But even here, the final judgment should reflect the uncertainty in the data.) Or that at least one person is ‘wrong’ (has a different answer than others). Among other things, this can stem from:
variation in skill, e.g., how to assess patent applications
variation in effort, e.g., some people put more effort than others
agency and preferences, e.g., I am a conservative judge, and I can deny an asylum application because I have the power to do so
biases like using irrelevant information, e.g., weather, hypoglycemia, etc.
(Note: a lack of variability doesn’t mean we are on to the right answer.)
The list of proposed solutions is extensive—from selecting better judges to the wisdom of the crowds to using models to training people better to more elaborate schemes like dividing the decision task and asking people to make relative than absolute judgments. The evidence backing the solutions is not always hefty, which meshes with the ideolog-like approach to evidence present everywhere in the book. When I did a small audit of the citations, three things stood out (the overarching theme is adherence to the “No Congenial Result Scrutinized or Left Uncited Act”):
Extremely small n studies cited without qualification. Software engineers. Quote from the book: “when the same software developers were asked on two separate days to estimate the completion time for the same task, the hours they projected differed by 71%, on average.” The underlying paper: “In this paper, we report from an experiment where seven experienced software professionals estimated the same sixty software development tasks over a period of three months. Six of the sixty tasks were estimated twice.”
Extremely small n studies cited without qualification. Israeli Judges. Hypoglycemia and judgment: “Our data consist of 1,112 judicial rulings, collected over 50 d in a 10-mo period, by eight Jewish-Israeli judges (two females) who preside over two different parole boards that serve four major prisons in Israel.”
Surprising but likely unreplicable results. “When calories are on the left, consumers receive that information first and evidently think “a lot of calories!” or “not so many calories!” before they see the item. Their initial positive or negative reaction greatly affects their choices. By contrast, when people see the food item first, they apparently think “delicious!” or “not so great!” before they see the calorie label. Here again, their initial reaction greatly affects their choices. This hypothesis is supported by the authors’ finding that for Hebrew speakers, who read right to left, the calorie label has a significantly larger impact..” (Paper.) “We show that if the effect sizes in Dallas et al. (2019) are representative of the populations, a replication of the six studies (with the same sample sizes) has a probability of only 0.014 of producing uniformly significant outcomes.” (Paper.)
Citations to HBR. Citations to think pieces in Harvard Business Review (10 citations in total based on a keyword search) and books like ‘Work Rules!’ for a fair many claims.
Say that there is a donation solicitation company. Say that there are 100M potential donors they can reach out to eachyear. Let’s also assume that the company gets paid on a contingency fee basis, getting a fixed percentage of all donations.
The company currently follows the following process: it selects 10M potential donors from the list using some rules and reaches out to them. The company gets donations from 2M donors. Also, assume that agents earn a fixed percentage of the dough they bring in.
What’s profit-maximizing staffing?
The company’s optimal strategy for staffing (depending on the risk preference) is:
where reflects the probability of donation from potential donor , is the value of the donation from the ith customer, is the contingency fee, and is the cost of reaching out to the potential donor.
Modeling can be challenging because the cost may be a function of donor attributes but also the granularity at which you can purchase labor, the need for specialists for soliciting donations from different potential donors, e.g., language, etc. For instance, classically, it may well be that you can only buy labor in chunks, e.g., full-time workers for some time. We leave these considerations out for now. We also take as fixed the optimal strategy to reach out to each donor.)
The data we have the greatest confidence in pertains to cases where we tried and observed an outcome. The data for the 10M can look like this:
We can use this data to learn a regression within the 10M and then use the model to predict the rank. If you use the model to rank the 10M you get next year, you can get greater profits from not pursuing the 8M. If you use it to rank the remaining 90M, you are making the assumption that donors who were not selected but are otherwise similar to those who were chosen, are similar in their returns. It is likely not the case.
To get better traction on the 90M, you need to get new data, starting with a random sample, and using deep reinforcement learning to figure out the kind of donors who are profitable to reach out to.
One conventional definition of group fairness is that the ML algorithms produce predictions where the FPR (or FNR or both) is the same across groups. Fixating on equating FPR etc. can harm the very groups we are trying to help. So it may be useful to rethink how to solve the problem of reducing unfairness.
One big reason why the FPR may vary across groups is that, given the data, some groups’ outcomes are less predictable than others. This may be because of the limitations of the data itself or because of the limitations of algorithms. For instance, Kearns and Roth in their book bring up the example of college admissions. The training data for college admissions is the decisions made by college counselors. College counselors may well be worse at predicting the success of minority students because they are less familiar with their schools, groups, etc., and this, in turn, may lead to algorithms performing worse on minority students. (Assume the algorithm to be human decision-makers and the point becomes immediately clear.)
One way to address worse performance may be to estimate the uncertainty of the prediction. This allows us to deal with people with wider confidence bounds separately from people with narrower confidence bounds. The optimal strategy for people with wider confidence bounds people may be to collect additional data to become more confident in those predictions. For instance, Komiyama and Noda propose something similar (pdf) to help overcome a lack of information during hiring. Or we may need to figure out a way to compensate people based on their uncertainty interval.
The average width of the uncertainty interval across groups may also serve as a reasonable way to diagnose this particular problem.
One definition of a fair algorithm is an algorithm that yields the same FPR across groups (an example of classification parity). To achieve that, we often have to trade in some accuracy. The final model is thus less accurate but fair. There are two concerns with such models:
Net Harm Over Relative Harm: Because of lower accuracy, the number of people from a minority group that are unfairly rejected (say for a loan application) may be a lot higher. (This is ignoring the harm done to other groups.)
Mismeasuring Harm? Consider an algorithm used to approve or deny loans. Say we get the same FPR across groups but lower accuracy for loans with a fair algorithm. Using this algorithm, however, means that credit is more expensive for everyone. This, in turn, may cause fewer people of the vulnerable group to get loans as the bank factors in the cost of mistakes. Another way to think about the point is that using such an algorithm causes net interest paid per borrowed dollar to increase by some number. It seems this common scenario is not discussed in many of the papers on fair ML. One reason for that may be that people are fixated on who gets approved and not the interest rate or total approvals.
“To get roughly 70% of the planet’s population inoculated by April, the IMF calculates, would cost just $50bn. The cumulative economic benefit by 2025, in terms of increased global output, would be $9trn, to say nothing of the many lives that would be saved.”
The Economist frames this as an opportunity for G7. And it is. But it is also an opportunity for third-world countries, which plausibly can borrow $50bn given the return on investment. The fact that money hasn’t already been allocated poses a puzzle. Is it because governments think about borrowing decisions based on whether or not a policy is tax revenue positive (which a 180x return ought to be even with low tax collection and assessment rates)? Or is it because we don’t have a marketplace where we can transact on this information? If so, it seems like an important hole.
Here’s another way to look at this point. Among countries where the profits mostly go to a few, why do the people at the top not come to invest together so that they can harvest profits later? Brunei is probably an ok example.
Two papers estimate the impact of having a daughter on Members of Congress’ (MC’s) position on women’s issues. Washington (2008) finds that each additional daughter (conditional on the number of children) causes about a 2 point increase in liberalism on women’s issues using data from the 105th to 108th Congress. Costa et. al 2019 use data from 110th to 114th Congress to find there is a noisily estimated small effect that cannot be distinguished from zero.
Same Number, Different Interpretation
Washington (2008) argues that a 2 point effect is substantive. But Costa et al. argue that a 2–3 point change is not substantively meaningful.
“In all five specifications, the score increases by about two points with each additional daughter parented. For all but the 106th Congress, the number of female children coefficient is significantly different from zero at conventional levels. While that two point increase may seem small relative to the standard deviations of these scores, note that the female legislators, on average, score a significant seven to ten points higher on these rating scores. In other words, an additional daughter has about 25% of the impact on women’s issues that one’s own gender has.”
“The lower bound of the confidence interval for the first coefficient in Model 1, the effect of having a daughter on AAUW rating, is −3.07 and the upper bound is 2.01, meaning that the increase on the 100-point AAUW scale for fathers of daughters could be as high as 2.01 at the 90% level, but that AAUW score could also decrease by as much as 3.07 points for fathers of daughters, which is in the opposite direction than previous literature and theory would have us expect. In both directions, neither the increase nor the decrease is substantively very meaningful.“
The two papers—Washington’s and Costa et al.—come to different conclusions. But why? Besides different data, there are fair many other differences in modeling choices including (p.s. this is not a comprehensive list):
How the number of children are controlled for. Washington uses fixed effects for the number of children. This makes sense if you conceive the number of daughters as a random variable within people with the same number of children. Another way to think of it is as a block randomized experiment. Costa et al. write, “Following Washington (2008), we also include a control variable for the total number of children a legislator has.” But control for it linearly.
Dummy Vs. Number of Daughters. Costa et al. have a ‘has daughter’ dummy that codes as 1 any MC with 1 or more daughter while Washington uses the number of daughters as the ‘treatment’ variable.
Common Issues
The primary dependent variable is votes chosen by an interest group. Doing so causes multiple issues. The first is incommensurability across time. The chosen votes are different because not only is the selection process in choosing the votes is likely different but also the selection process that goes into what things come to vote. So it could be the case that the effect hasn’t changed but the measurement instrument has. The second issue is that interest groups are incredibly strategic in choosing the votes. And that means they choose votes that don’t always have a strong, direct, unique, and obvious relationship to women’s welfare. For instance, AAUW chose the vote to confirm Neil Gorsuch as one of the votes. There are likely numerous considerations that go into voting for Neil Gorsuch, including conflicting considerations about women’s welfare. For instance, a senator who supports the women’s right to choose may vote for Neil Gorsuch even if there is concern that the judge will vote against it because they may think Gorsuch would support liberalizing the economy further which will have a beneficial impact on women’s economic status, which the senator may view as more important. Third, the number of votes chosen is tiny. For the 115th Congress, for the Senate, there are only 7 votes and only 6 for the House of Representatives. Fourth, it seems the papers treat the House of Representatives and Senate interchangeably when the votes are different. Fifth, one of the issues with imputing ideology from congressional votes is that the issues over which people get to express preferences is limited. So the implied differences are generally smaller than actual ideological differences. The point affects how we interpret the results.
“[Q]uotas are often thought of as temporary measures, used to improve the lot of particular groups of people until they can take care of themselves.”
Bhavnani 2011
So how quickly can be withdraw the quota? The answer depends—plausibly on space, office, and time.
“In West Bengal …[i]n 1998, every third G[ram] P[anchayat] starting with number 1 on each list was reserved for a woman, and in 2003 every third GP starting with number 2 on each list was reserved” (Beaman et al. 2012). Beaman et al. exploit this random variation to estimate the effect of reservation in prior election cycles on women being elected in the subsequent elections. They find that 1. just 4.8% of the elected ward councillors in non-reserved wards, 2. this number doesn’t change if a GP has been reserved once before, and 3. shoots up to a still-low 10.1% if the GP has been reserved twice before (see the last column of Table 11 below).
From Beaman et al. 2012
In a 2009 article, Bhavnani, however, finds a much larger impact of reservation in Mumbai ward elections. He finds that a ward being reserved just once before causes a nearly 18 point jump (see the table below) starting from a lower base than above (3.7%).
From Bhavnani 2009
p.s. Despite the differences, Beaman et al. footnote Bhavnani’s findings as: “Bhavnani (2008) reports similar findings for urban wards of Mumbai, where previous reservation for women improved future representation of women on unreserved seats.”
Beaman et al. also find that reservations reduce men’s biases. However, a 2018 article by Amanda Clayton finds that this doesn’t hold true (though the CI are fairly wide) in Lesotho, Kenya.
In late 2019, in a lecture at the Watson Center at Brown University, Raghuram Rajan spoke about the challenges facing the Indian economy. While discussing the trends in growth in the Indian economy (I have linked to the relevant section in the video. see below for the relevant slide), Mr. Rajan notes:
“We were growing really fast before the great recession, and then 2009 was a year of very poor growth. We started climbing a little bit after it, but since then, since about 2012, we have had a steady upward movement in growth going back to the pre-2000, pre-financial crisis growth rates. And then since about mid-2016 (GS: a couple of years after Mr. Modi became the PM), we have seen a steady deceleration.”
Raghuram Rajan at the Watson Center at Brown in 2019 explaining the graph below
The statement is supported by the red lines that connect the deepest valleys with the highest peak, eagerly eliding over the enormous variation in between (see below).
See Something, Say Some Other Thing
Not to be left behind, Mr. Rajan’s interlocutor Mr. Subramanian shares the following slide about investment collapse. Note the title of the slide and then look at the actual slide. The title says that the investment (tallied by the black line) collapses in 2010 (before Mr. Modi became PM).
Epilogue
If you are looking to learn more about some of the common techniques people use to lie with charts, you can read How Charts Lie. (You can read my notes on the book here.)






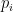 reflects the probability of donation from potential donor
reflects the probability of donation from potential donor  ,
, 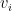 is the value of the donation from the ith customer,
is the value of the donation from the ith customer,  is the contingency fee, and
is the contingency fee, and 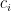 is the cost of reaching out to the potential donor.
is the cost of reaching out to the potential donor. 



