Say you want to measure how often people visit pornographic domains over some period. To measure that, you build a model to predict whether or not a domain hosts pornography. And let’s assume that for the chosen classification threshold, the False Positive rate (FP) is 10\% and the False Negative rate (FN) is 7\%. Here below, we discuss some of the concerns with using scores from such a model and discuss ways to address the issues.
Let’s get some notation out of the way. Let’s say that we have 



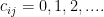
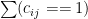
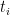

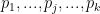
Let’s start with a simple point. Say there are 5 domains with 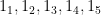
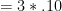

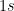
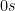
Read more here.