Say that you want to predict wait times at restaurants using data with four columns: wait times (wait), the restaurant name (restaurant), time and date of observation. Using the time and date of the observation, you create two additional columns: time of the day (tod) and day of the week (dow). And say that you estimate the following model:
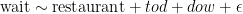
Assume that the number of rows is about 100 times the number of columns. There is little chance of overfitting. But you still do an 80/20 train/test split and pick the model that works the best OOS.
You have every right to expect the model’s performance to be close to its OOS performance. But when you deploy the model, the model performs much worse than that. What could be going on?
In the model, we estimate a restaurant level intercept. But in estimating the intercept, we use data from all wait times, including those that happened after the date. One fix is to using rolling averages or last X wait times in the regression. Another is to more formally construct the data in such a way that you are always predicting the next wait time.