Why do many people think that people on the other side are not well motivated? It could be because they think that the other side is less moral than them. And since opprobrium toward the morally defective is the bedrock of society, thinking that the people in the other group are less moral naturally leads people to censure the other group.
But it can’t be that two groups simultaneously have better morals than the other. It can only be that people in the groups think they are better. This much logic dictates. So, there has to be a self-serving aspect to moral standards. And this is what often leads people to think that the other side is less moral. Accepting this is not the same as accepting moral relativism. For even if we accept that some things are objectively more moral—not being sexist or racist say—some groups—those that espouse that a certain sex is superior or certain races are better—will still think that they are better.
But how do people come to know of other people’s morals? Some people infer morals from political aims. And that is a perfectly reasonable thing to do as political aims reflect what we value. For instance, a Republican who values ‘life’ may think that Democrats are morally inferior because they support the right to abortion. But the inference is fraught with error. As matters stand, Democrats would also like women to not go through the painful decision of aborting a fetus. They just want there to be an easy and safe way for women should they need to.
Sometimes people infer morals from policies. But support for different policies can stem from having different information or beliefs about causal claims. For instance, Democrats may support a carbon tax because they believe (correctly) the world is warming and because they think that the carbon tax is what will help reduce global warming the best and protect American interests. Republicans may dispute any part of that chain of logic. The point isn’t what is being disputed per se, but what people will infer about others if they just had information about the policies they support. Hanlon’s razor is often a good rule.






 is population of
is population of 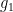 in the ith area
in the ith area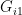 is population of
is population of 







